Introducción
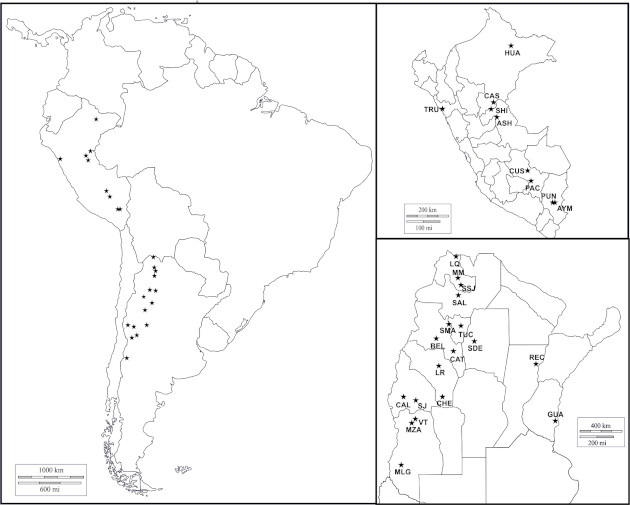
La ciudad de Trujillo, capital del departamento de La Libertad, constituye la tercera área metropolitana más poblada de Perú, después de Lima y Arequipa (Instituto Nacional de Estadística e Informática [INEI], 2012) (Figura 1). Se localiza sobre la costa del Pacífico, a 550 km al norte de la capital nacional, en el antiguo valle de “Chimo”, hoy Valle de Moche o Santa Catalina (Jack, López, López, 2010).
Figura 1:
Localización geográfica y siglas de las poblaciones incluidas en este trabajo TRU: Trujillo, HUA: Huambisa, CAS: Cashibo; SHI: Shinibo; ASH: Ashaninka, PAC: Pacarictampu, PUN: Puno; AYM: Aimara; CUS: Cusco (incluye las localidades de San Sebastián y San Jerónimo); LQ: La Quiaca, MM: Maimará, JUJ: San Salvador de Jujuy, SAL: Salta, SMA: Santa María, BEL: Belén, TUC: San Miguel de Tucumán, SDE: Santiago del Estero, CAL: Calingasta, CAT: San Fernando del Valle de Catamarca, LR: La Rioja, SJ: San Juan, CHE: Chepes, VT: Villa Tulumaya, MZA: Mendoza, MLG: Malargüe, REC: Reconquista, GUA: Gualeguaychú.
Se estima que en el actual territorio de Perú se han desarrollado diferentes culturas desde aproximadamente el año 10.000 AP (antes del presente). Estudios arqueológicos aportan evidencias del establecimiento de civilizaciones con altos niveles de organización social y desarrollo tecnológico. El máximo exponente fue el Imperio Inca, cuyo apogeo de expansión política y territorial se dio entre los siglos XV y XVI.
En el siglo XVI, con la conquista y colonización europea se inició un largo y sostenido proceso de mestizaje. La población migrante extracontinental tenía dos orígenes principales, por un lado, europeo, en su mayoría procedente de la península ibérica y, por otro, africano. Millones de individuos fueron capturados y trasladados contra su voluntad desde África hacia América, para ocupar labores esencialmente agrícolas, pero también realizar otras actividades como minería, industria, comercio y servicio doméstico. Sin su forzosa participación, la economía de las colonias de ultramar no hubiera podido desarrollarse (Haro Hidalgo, 2019). En el caso específico de la costa de Perú, el comercio esclavista abasteció de mano de obra para explotación de las plantaciones de caña de azúcar, con un incremento notable de este mercado a partir del siglo XVIII (Hunefeldt, 2004).
Durante los siglos XIX y XX, el gobierno del Perú fomentó la inmigración de trabajadores asiáticos, quienes inicialmente se emplearon también en las plantaciones costeras y más tarde fueron migrando hacia las grandes ciudades. Durante este período, se llevaron a cabo proyectos de expansión territorial y se dictaron leyes para promover la inmigración europea, pero estas medidas tuvieron poco éxito debido a que, para aquellos que quisieran migrar a América, existían mejores ofertas por parte de otros países, tales como Argentina, Chile o Estados Unidos.
Entre 1876 y 1940, la población de Perú experimentó un crecimiento demográfico notable, pero este fenómeno tuvo una espacialidad heterogénea, se centró casi exclusivamente en la zona de la costa y en los aglomerados urbanos como Lima, Arequipa, Cuzco y Trujillo. Este crecimiento fue a expensas de migraciones internas, que comenzaron en 1920, desde el campo hacia las ciudades. El porcentaje de la población que residía en zonas rurales cayó de un 65% en 1940, al 30% en 1970 (Hunefeldt, 2004).
En 2017, se desarrolló el último censo nacional de población, que evidenció un total de 31 millones 237 mil 385 habitantes, con lo que Perú se posiciona como el quinto país más densamente poblado de América Latina (INEI, 2018). Cerca del 80% de la población vive en el área urbana (23.311.893 habitantes), los cuales representan el 79,3% del total nacional; mientras que en el área rural fueron censadas 6.690.991 personas (20,7%). El censo previo había sido en el año 2007, es decir, durante el plazo de una década, la población urbana se incrementó en 17,3%, equivalente a 343.454 personas por año, es decir, una tasa promedio anual del 1,6%. La población rural disminuyó en 19,4%, es decir, una tasa promedio anual decreciente de -2,1%.
En el Perú moderno se consideran mestizas a aquellas personas que hablan español y se comportan de acuerdo con patrones socioculturales que, históricamente, han sido identificados con los sectores hispánicos de la sociedad. Esto significa que individuos con un origen genético indígena sean considerados mestizos por su estilo de vida, idioma o comportamiento. De la misma manera, una persona que tiene ancestros provenientes de diferentes etnias pero vive en una comunidad aborigen y habla quechua es considerada indígena (Hunefeldt, 2004). Como consecuencia, los datos obtenidos de censos o encuestas no reflejan la composición genética de la población, sino categorías socioculturales.
Con base en lo anterior, el presente trabajo se propone determinar el origen continental de una muestra masculina de la población actual de Trujillo, a través del análisis de los linajes paternos del cromosoma Y. Además, se realizan inferencias sobre el grado de diferenciación poblacional, se deducen niveles de mestizaje y se comparan los resultados con los encontrados en otras poblaciones de Perú y Argentina, en busca de posibles semejanzas genéticas.
Sujetos y métodos
Consideraciones éticas. El proyecto cuenta con la aprobación del Comité de Ética del IMBICE (CONICET-UNLP-CIC) y de la Unidad Territorial de Salud Nº 6 (Trujillo Este, Gobierno Regional de La Libertad). Los donantes son personas que asistieron a diferentes centros de salud públicos y privados de la ciudad de Trujillo y voluntariamente expresaron su voluntad de participar, a través de la firma del Término de Consentimiento Informado. Los voluntarios aportaron material biológico e información básica acerca de su lugar de nacimiento, el de sus padres y abuelos, y expresaron su deseo de recibir los resultados sobre ancestralidad continental de los linajes uniparentales (ADNmt y Cromosoma Y), información que se les comunicó de manera individual, a través de un correo electrónico. Las muestras biológicas fueron anonimizadas al llegar al laboratorio y en todo momento se preservó la identidad de las personas.
Características de la muestra. Se colectaron 101 muestras de sangre periférica correspondientes a individuos de sexo masculino, no emparentados biológicamente, residentes de la ciudad de Trujillo, de las que de obtuvo ADN por precipitación salina con cloruro de sodio (Miller et al., 1988).
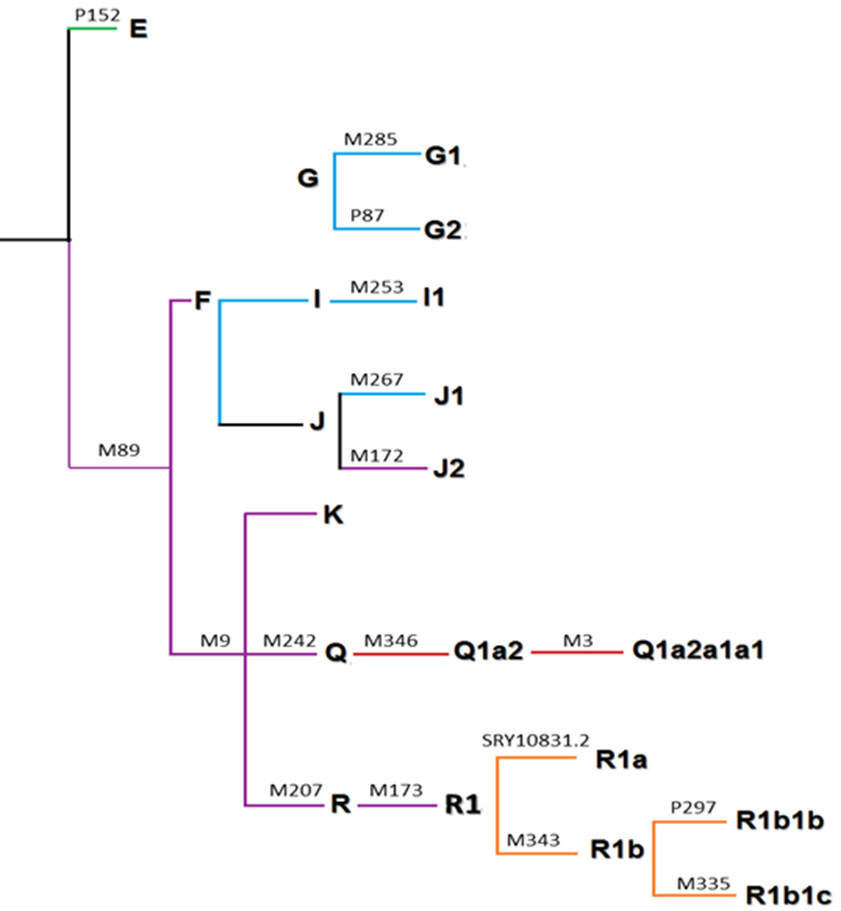
Tipificación de los haplogrupos del cromosoma Y. Se recurrió a un método de amplificación alelo-específica para la identificación de un total de 17 marcadores bialélicos (SNPs, por las siglas en inglés de Single nucleotide polymorphisms) que determinan haplogrupos autóctonos y alóctonos de América, reportados en la bibliografía como los más frecuentes en poblaciones de Argentina (Bailliet et al., 2011): E, F, G1, G2, I1, J1, J2, K, Q, R y R1, mediante la tipificación de los SNPs P152, M89, M285, P87, M253, M267, M172, M9, M242, M207 y M173 respectivamente. Se tipificaron además Q1a1 y Q1a1a3, subhaplogrupos del clado Q, por medio de los SNPs M242, M346 y M3. Cuando los linajes solo pudieron ser identificados por M242 se denominaron Q*. Los subhaplogrupos R1a, R1b, R1b1b y R1b1c se reconocieron utilizando los marcadores SRY10831.2, M343, P297 y M335 (Karafet et al., 2008) (Figura 2).
Se emplearon reacciones PCR-AFLP multiplex utilizando un conjunto de oligonucleótidos previamente diseñados (Jurado Medina et al., 2014).
Figura 2
Árbol filogenético simplificado del cromosoma Y, en el que se hallan resaltados, en rojo, el haplogrupo nativo de América, y en azul, los haplogrupos alóctonos (Europa, Medio Oriente y África) considerados en este trabajo (Jurado Medina, 2015).
Análisis interpoblacional. La distribución de haplogrupos del cromosoma Y encontrada en Trujillo se comparó con datos disponibles de otras muestras poblacionales de Perú y de Argentina, para investigar afinidades genéticas en un contexto regional. Se utilizaron datos de las localidades de La Quiaca, Maimará, San Salvador de Jujuy, Salta, Santa María, Belén, San Miguel de Tucumán, Santiago del Estero, Calingasta, Catamarca, San José, La Rioja, San Juan, Chepes, Lavalle, Mendoza y Malargüe, tipificadas previamente en el laboratorio de Genética Molecular de Poblaciones del IMBICE. Además, se incluyeron en el análisis datos provenientes de 10 poblaciones del Perú (Figura 1) disponibles en la bibliografía (Fonseca Pinto Leite, 2018; Sandoval et al., 2018; Di Corcia et al., 2017; Neyra-Rivera et al., 2021). Estas muestras representan mayoritariamente a poblaciones nativas rurales, a diferencia de la muestra de Trujillo, que proviene de un contexto urbano cosmopolita.
La estructura genética de la población se investigó por medio del análisis molecular de la varianza (AMOVA) (Weir y Cockerham, 1984; Excoffier, Smouse y Quattro, 1992), utilizando el programa Arlequin 3.0 (Excoffier y Schneider, 2005), mientras que las similitudes genéticas relativas entre muestras poblacionales se evaluaron a través del análisis de componentes principales con el programa Past 4 (Hammer, Harper y Ryan, 2001).
Resultados
Frecuencia de haplogrupos del cromosoma Y. El haplogrupo más frecuente en la muestra de Trujillo fue Q, identificado en el 46,6% de los voluntarios. Dentro de este clado, el subhaplogrupo Q-M3 representa el 41,5% y Q-M346 el 4% del total de individuos, el 1% restante corresponde al haplogrupo Q*. El haplogrupo R fue el segundo más representado (25,8%); el subclado R-P297 (R1b1b) fue el mayoritario, con el 21,7% del total, mientras que un 3% de las muestras fueron asignadas al subhaplogrupo R-M173 (R1) y solo el 1% a R-SRY10831.2 (R1a). El siguiente clado en términos de frecuencias fue F, y comprende el 6,9% del total. Los subhaplogrupos F (xG2, J1, J2), J-M172 (J2) y G-P87 (G2) se hallaron en 6,9%, 4% y 5%, respectivamente, mientras que el haplogrupo K está presente en un 5% de los individuos. Finalmente, el clado E fue identificado en un 6,9% del total (Tabla 1).
Tabla 1
Frecuencia de haplogrupos del cromosoma Y en la población de Trujillo, Perú.
|
Haplogrupos |
N |
% |
|
E |
7 |
6,9 |
|
F(XG2,J1,J2) |
7 |
6,9 |
|
G2 |
4 |
5 |
|
J1 |
1 |
1 |
|
J2 |
4 |
4 |
|
K |
5 |
5 |
|
Q* |
1 |
1 |
|
Q1a2 |
4 |
4 |
|
Q1a2a1a1 |
42 |
41,5 |
|
R1 |
3 |
3 |
|
R1a |
1 |
1 |
|
R1b1b |
22 |
21,7 |
|
Total |
101 |
100,00 % |
Estructura de la población
Para investigar la posible existencia de estructura genética en la distribución de haplogrupos paternos a nivel interpoblacional, se realizó un análisis molecular de la varianza (AMOVA) incluyendo muestras nativas de Perú y de poblaciones urbanas de Argentina (Tabla 2).
Tabla 2
Frecuencia de los haplogrupos del cromosoma Y en muestras del presente estudio y de la bibliografía.
|
País |
Localidad |
E |
F* |
G |
I1 |
J |
K(xQ,R) |
Q* |
Q-M346 |
Q-M3 |
R |
Total |
|
Perú |
Trujillo |
0,069 |
0,069 |
0,0396 |
0 |
0,05 |
0,05 |
0,01 |
0,04 |
0,416 |
0,257 |
101 |
|
Ashaninka |
0,017 |
0 |
0,017 |
0 |
0 |
0,034 |
0,017 |
0,017 |
0,881 |
0,017 |
59 |
|
San Sebastián y San Jerónimo |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
29 |
|
Pacarictampu |
0 |
0,067 |
0 |
0 |
0 |
0 |
0 |
0 |
0,8 |
0,133 |
15 |
|
Cusco |
0,333 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0,333 |
0,334 |
3 |
|
Puno |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0,667 |
0,333 |
3 |
|
Shipibo |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
22 |
|
Cashibo |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
28 |
|
Ashaninka |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
8 |
|
Huambisa |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0,313 |
0,688 |
0 |
16 |
|
Aimara |
0,034 |
0 |
0,0337 |
0 |
0 |
0,011 |
0 |
0 |
0,865 |
0,056 |
89 |
|
Argentina |
La Quiaca |
0,097 |
0,083 |
0 |
0 |
0,042 |
0,028 |
0 |
0 |
0,389 |
0,361 |
72 |
|
Maimará |
0,048 |
0,058 |
0,0288 |
0 |
0,087 |
0,067 |
0 |
0,019 |
0,49 |
0,202 |
104 |
|
Jujuy |
0 |
0,054 |
0 |
0 |
0,027 |
0,081 |
0 |
0,081 |
0,405 |
0,351 |
37 |
|
Salta |
0,136 |
0,012 |
0,0123 |
0 |
0,086 |
0,086 |
0 |
0,012 |
0,407 |
0,247 |
81 |
|
Santa María |
0,063 |
0,078 |
0,0625 |
0 |
0,109 |
0,063 |
0 |
0,047 |
0,188 |
0,391 |
64 |
|
Belén |
0,089 |
0,161 |
0,0357 |
0 |
0,179 |
0 |
0 |
0,071 |
0,179 |
0,286 |
56 |
|
Tucumán |
0,147 |
0,064 |
0,1346 |
0,071 |
0,064 |
0,032 |
0 |
0,013 |
0,077 |
0,397 |
156 |
|
Santiago del Estero |
0,124 |
0,2 |
0 |
0 |
0,082 |
0,024 |
0,006 |
0,018 |
0,035 |
0,512 |
170 |
|
San José |
0 |
0,143 |
0 |
0 |
0,143 |
0 |
0 |
0 |
0,429 |
0,286 |
7 |
|
Catamarca |
0,094 |
0,01 |
0,0417 |
0 |
0,073 |
0,042 |
0 |
0,042 |
0,115 |
0,583 |
96 |
|
La Rioja |
0,149 |
0,057 |
0,069 |
0 |
0,08 |
0,08 |
0 |
0,011 |
0,103 |
0,448 |
87 |
|
San Juan |
0,115 |
0,038 |
0,0192 |
0 |
0,192 |
0,058 |
0 |
0,048 |
0,077 |
0,452 |
104 |
|
Chepes |
0,083 |
0 |
0 |
0 |
0,167 |
0,042 |
0,042 |
0 |
0,083 |
0,583 |
24 |
|
Villa Tulumaya |
0 |
0,194 |
0,0556 |
0 |
0,056 |
0 |
0 |
0,028 |
0,167 |
0,5 |
36 |
|
Mendoza |
0,141 |
0,077 |
0,0385 |
0 |
0,154 |
0,026 |
0 |
0 |
0,09 |
0,474 |
78 |
|
Malargüe |
0 |
0,098 |
0 |
0 |
0,171 |
0,024 |
0 |
0,024 |
0,073 |
0,61 |
41 |
|
Reconquista |
0,117 |
0,183 |
0 |
0 |
0,05 |
0,183 |
0 |
0 |
0,067 |
0,4 |
60 |
|
Gualeguaychú |
0 |
0 |
0 |
0 |
0,103 |
0 |
0 |
0 |
0,026 |
0,872 |
39 |
Se realizaron tres análisis. En primer lugar, se incluyeron todas las muestras en un grupo único, se encontró una diferenciación altamente significativa (p < 0.01) (Tabla 3). A continuación, se separó el universo muestral en dos grupos, las muestras peruanas por un lado y las argentinas por el otro. En un primer análisis, se agrupó a Trujillo con las muestras peruanas y, en un segundo término, se lo agrupó con las argentinas, teniendo en cuenta que se trata de una población urbana cosmopolita. Ambos análisis mostraron diferencias estadísticamente significativas (p < 0,01), tanto en la variación entre poblaciones dentro de grupos como en la diferenciación entre grupos. Sin embargo, se advierte que Trujillo es más semejante al grupo peruano que al argentino, ya que el primer análisis muestra una varianza dentro de grupo menor (4,79% vs. 6,23%), es decir, una mayor similitud con las demás muestras, y una variación entre grupos sensiblemente mayor (32,24% vs. 25,36%) que cuando se lo incluye con las muestras urbanas argentinas.
Tabla 3
Resultados de análisis molecular de la varianza
|
Análisis |
Porcentaje de variación |
|
Dentro de poblaciones |
Entre poblaciones dentro de grupos |
Entre grupos |
|
Un grupo |
80,92 |
- |
19,08* |
|
Dos grupos1 |
62,97 |
4,79* |
32,24* |
|
Dos grupos2 |
68,41 |
6,23* |
25,36* |
Afinidades poblacionales
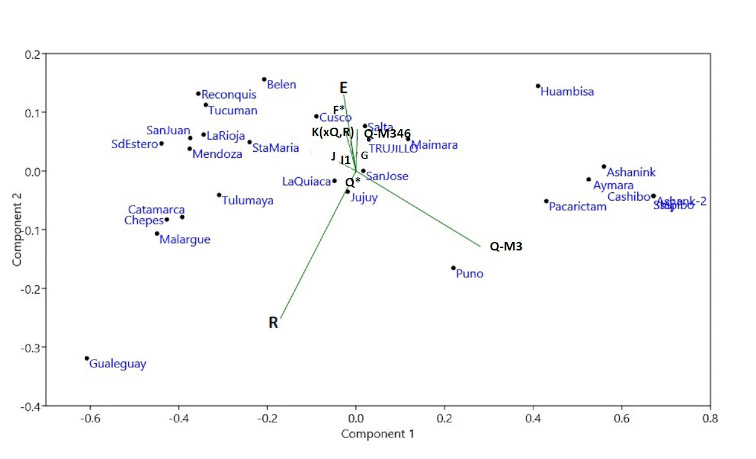
Para evaluar las afinidades relativas entre las muestras incluidas en el estudio interpoblacional se llevó a cabo un análisis de componentes principales (ACP) basados en las frecuencias de haplogrupos del cromosoma Y, partiendo de una matriz de varianzas-covarianzas. En el gráfico de la Figura 3 se proyectan las muestras y los haplogrupos simultáneamente en los dos primeros componentes principales, que representan conjuntamente el 93,2% de la variabilidad total. El primer componente da cuenta del 88% de la variación total, y está conformado mayoritariamente por la variación aportada por Q-M3 (con peso positivo) y R (con peso negativo). A la izquierda del gráfico se ubican la mayoría de las poblaciones argentinas, con mayor proporción de linajes europeos, particularmente Gualeguaychú, en el extremo inferior izquierdo de la figura debido a la alta incidencia del haplogrupo R. A la derecha del gráfico se agrupan las poblaciones peruanas, cercanas unas de otras, como consecuencia de las altas frecuencias del linaje americano Q-M3. Trujillo ocupa una posición central, más próxima a algunas muestras del extremo norte argentino (Salta, Maimará, San José, La Quiaca y San Salvador de Jujuy), todas con valores relativamente altos de Q-M3 e intermedios de R.
Figura 3
Gráfica de análisis de componentes principales (PC), que destaca las similitudes genéticas entre las poblaciones (círculos negros, Argentina; puntos grises, Perú), según haplogrupos del cromosoma Y: E, F*, K(xQ,R), J, J1,G, Q*, Q-M346, Q-M3. Siglas de las poblaciones TRU: Trujillo, HUA: Huambisa, CAS: Cashibo; SHI: Shinibo; ASH: Ashaninka, PAC: Pacarictampu, PUN: Puno; AYM: Aimara; CUS: Cusco (incluye las localidades de San Sebastián y San Jerónimo); LQ: La Quiaca, MM: Maimará, JUJ: San Salvador de Jujuy, SAL: Salta, SMA: Santa María, BEL: Belén, TUC: San Miguel de Tucumán, SDE: Santiago del Estero, CAL: Calingasta, CAT: San Fernando del Valle de Catamarca, LR: La Rioja, SJ: San Juan, CHE: Chepes, VT: Villa Tulumaya, MZA: Mendoza, MLG: Malargüe, REC: Reconquista, GUA: Gualeguaychú. TRU: Trujillo, HUA: Huambisa, CAS: Cashibo; SHI: Shinibo; ASH: Ashaninka, PAC: Pacarictampu, PUN: Puno; AYM: Aimara; CUS: Cusco (incluye las localidades de San Sebastián y San Jerónimo); LQ: La Quiaca, MM: Maimará, JUJ: San Salvador de Jujuy, SAL: Salta, SMA: Santa María, BEL: Belén, TUC: San Miguel de Tucumán, SDE: Santiago del Estero, CAL: Calingasta, CAT: San Fernando del Valle de Catamarca, LR: La Rioja, SJ: San Juan, CHE: Chepes, VT: Villa Tulumaya, MZA: Mendoza, MLG: Malargüe, REC: Reconquista, GUA: Gualeguaychú.
Discusión
En el censo nacional de Perú de 1940 se registró la composición étnica de la población. En ese momento, el 52,89% de los habitantes de ese país declaró ser de origen blanco o mestizo, mientras que un 45,86% se identificó como aborigen. Además, el 0,47% del total de individuos censados afirmó ser descendiente de africanos; el 0,68% dijo tener antepasados asiáticos (provenientes de China y Japón); y el 0,10% restante no declaró su ascendencia (Hunelfeldt, 2004). En el año 2017 se incluyó la pregunta sobre autoidentificación étnica, que les fue realizada únicamente a aquellas personas mayores de 12 años al momento del censo (un total de 23.196.391 habitantes). La mayoría (60,2%) se autoidentificó como mestizo; mientras que el 22,3% de la población encuestada se autoidentificó como quechua, y el 2,4% como de origen aimara. Asimismo, se registraron 79.266 personas que dijeron ser nativas/indígenas de la Amazonía; Ashaninka (55.489); Awajún (37.690); Shipibo Konibo (25.222) y 49.838 censados manifestaron ser de otro pueblo indígena u originario. El 6% se autoidentificó como segunda o tercera generación descendiente de migrantes asiáticos, el 5,9% como blanco y el 3,6% como afrodescendiente. El resto de las personas indicaron una categoría “Otro origen” sin mayor detalle y/o no respondieron a la pregunta (INEI, 2018).
En la comparación de la información demográfica con la genética, vemos que el porcentaje en el que se registró el haplogrupo nativo en la muestra de Trujillo se asemeja a la proporción de individuos que se identificaron como indígenas en el censo de 1940 en la misma ciudad (Carbajal-Caballero et al., 2005) y a las frecuencias haplotípicas originarias del continente americano reportadas en poblaciones de los Andes Centrales peruanos (Cabana et al., 2015). Este hallazgo concuerda además con la historia de la ciudad y la región, cuna de importantes culturas precolombinas, que continuaron vigentes luego de la Conquista, y foco de importantes actividades económicas.
Fonseca Pinto Leite (2018) analizó muestras de ADN de la comunidad Ashaninka, ubicada en el margen de los ríos amazónicos Pichis y Palcazú, en los Andes peruanos. En ese estudio se encontró que el 63% de los linajes fueron Q-M3, mientras que 30,6% fueron sublinajes de Q-M3, tales como Q-Z19319 (4,1%), Q-Z199483 (2%), Q-SA05 (24,55), y los linajes ancestrales para M3, representados por Q-P36 (1,8%) y Q-M346 (1,8%). Sandoval et al. (2018) estudiaron 18 individuos pertenecientes a 12 familias provenientes de los distritos San Sebastián y San Jerónimo de Cusco, que parecen estar vinculadas a los gobernantes incas. En esas muestras, la mayoría de los linajes fueron Q-M3 y también se identificaron tres sublinajes de Q-M3: Q-CTS51780 (1 individuo), Q-SA01 (1 individuo) y Q-Z19483 (7 individuos). Los autores sugieren que se trata de un linaje conectado con una expansión reciente en los Andes, con una antigüedad similar a la de la expansión Inca en el continente (Sandoval et al., 2018). Di Corcia y colaboradores (2017) analizaron 162 muestras provenientes del Amazonas peruano, de las comunidades Cashibo, Shipibo, Ashaninka y Huambisa de los departamentos de Ucayali y Loreto. En ese estudio, la gran mayoría de los linajes fueron Q-M3, y solo se encontraron linajes Q-M346 en la comunidad de Huambisa. Neyra-Rivera y colaboradores (2021) analizaron 90 individuos aimara de la ciudad de Puno, una de las más altas de Perú, a orillas del lago Titicaca. Del total de muestras, el 86,52% pertenecieron al haplogrupo Q, y también se encontraron haplogrupos R (5,62%), G (3,37%), E (3,37%) y J (1,12%). Sin embargo, es importante destacar que en este último trabajo la asignación de los haplogrupos se realizó a través de STRs (por su designación en inglés, Short Tandem Repeats). A diferencia de los marcadores bialélicos de tipo SNP, estos loci contienen elementos secuenciales cortos y repetitivos que varían en tamaño (3 a 7 pares de bases de longitud). Estas tandas repetitivas son abundantes y están ampliamente distribuidas en el genoma. Su alta tasa de mutación los vuelve una fuente muy rica de marcadores muy polimórficos, de gran utilidad en estudios forenses o en determinaciones de parentesco. Neyra-Ribera y colaboradores (2021) construyeron haplotipos en base a 17 STR del cromosoma Y, y asignaron luego el haplogrupo más probable de acuerdo con el haplotipo individual con un software on-line, pero sin determinarlo molecularmente.
En las muestras de Argentina y de Trujillo, nuestro grupo ha identificado los subhaplogrupos Q-P36, Q-M346 y Q-M3. Hemos propuesto un origen americano del subhaplogrupo Q-M346, fundamentado en la red de haplotipos de 17 STRs de linajes Q-M346 presentes en distintos países de Sudamérica y el Sudeste Asiático. En tanto, Q-P36 posiblemente sea de origen alóctono. Compilamos linajes de diversas regiones del planeta y las muestras de Argentina fueron cercanas o idénticas a linajes de Medio Oriente (Jurado Medina et al., 2020) (Tabla 2).
El segundo linaje más frecuente en la población fue R, considerado característico de Europa dada su alta incidencia en ese continente (Underhill et al., 2010; Myres et al., 2011). Dentro del R-M173, el subhaplogrupo R-P297 fue hallado en el 21,7% del total de individuos analizados. La proporción relativamente alta de portadores de dicho haplogrupo está ligada principalmente a la llegada de los conquistadores españoles, que en etapas tempranas fueron casi en su totalidad de sexo masculino, y al posterior arribo de nuevos inmigrantes europeos entre fines del siglo XIX y el siglo XX. La incidencia de este haplogrupo reportada en publicaciones anteriores sobre poblaciones peruanas varía de 0 a 33% (Di Corcia et al., 2017; Fonseca Pinto Leite, 2018; Sandoval et al., 2018; Neyra-Rivera et al., 2021) (Tabla 2).
El haplogrupo alóctono F comprende los clados G, H, I, J y K. Dentro del haplogrupo G, se testearon los subhaplogrupos G-M285 y G-P87, pero solo se halló G-P87 en una proporción del 45%. Esto puede explicarse teniendo en cuenta que G-M285 se encuentra prácticamente ausente en Europa. En cambio, G-P87 es más frecuente en Europa occidental, región desde la cual Perú recibió varias oleadas de inmigrantes (Cinnioğlu et al., 2004; Rootsi et al., 2012). Solo en las muestras peruanas de Ashaninka y Aimara se reportó la existencia del haplogrupo G (Fonseca Pinto Leite, 2018; Sandoval et al., 2018; Neyra-Rivera et al., 2021), sin distinción entre los subhaplogrupos analizados en el presente trabajo (Tabla 2).
Se analizó también el linaje J, y se encontró una mayor proporción de J-M172 con respecto a J-M267. Estos haplogupos tienen origen en el Cercano Oriente, norte de África y Europa, mientras que J-M172 presenta una distribución más amplia, como consecuencia de la dispersión árabe a lo largo del continente europeo (Cinnioğlu et al., 2004; Semino et al., 2004). Es probable, por lo tanto, que los cromosomas asociados a este clado se hayan introducido en la población de Trujillo a través de inmigrantes provenientes de Europa. Era esperable la baja incidencia del haplogrupo J-M267, en comparación con su linaje hermano J-M172, ya que presenta una dispersión hacia el sudeste de Europa, desde donde no existen registros históricos de migraciones hacia Perú. En la bibliografía consultada, solo se reportó la presencia del haplogrupo J en poblaciones aimara (Neyra-Rivera et al., 2021) (Tabla 2).
Al igual que en el noroeste de Argentina (Jurado Medina, 2015), no se encontró ningún cromosoma identificado con el haplogrupo I, muy extendido en el norte de Europa, pero es poco frecuente en el resto del mundo (Cinnioğlu et al., 2004; Rootsi et al., 2012). Dado que en el presente trabajo no se analizaron los haplogrupos I2, es probable que algunas de las muestras asignadas al clado F* correspondan a ese haplogrupo. Cabe consignar que las muestras asignadas al clado F* presentaron un estado derivado para el marcador M89, pero ancestral para M172, P287, M253, M267 y M285. Sandoval y colaboradores (2018) mencionan una muestra con subhaplogrupo I2, que en nuestro análisis estaría agrupado en los subhaplogrupos F* (Tabla 2).
El 5% de los cromosomas Y analizados portadores de la mutación M9 pero que no corresponden al clado Q ni R fueron asignados al haplogrupo K. Dentro de este grupo se encuentran los subclados L, M, N, O, S y T. Es posible que estos individuos pertenezcan al linaje O, que es característico del este de Asia, de donde Perú recibió inmigrantes en dos momentos históricos diferentes. Proporciones similares se encontraron en poblaciones de Bolivia y Argentina (Cárdenas Paredes, 2014; Jurado Medina, 2015; Fonseca Pinto Leite, 2018) (Tabla 2). También podrían pertenecer al subclado T-M70 que ha sido descripto en frecuencias variables en Asia del este, África y Europa (Karafet et al., 2008; Méndez et al., 2011). Cabe destacar que un individuo con haplogrupo T fue descripto en Puno (Sandoval et al., 2018).
Dado que no se profundizó en la caracterización de los subhaplogrupos del clado E, presente en el 6,9% de las muestras, no es posible distinguir si estos individuos son descendientes de europeos o de africanos. Como se ha mencionado, los esclavos introducidos durante la época colonial podrían tener presencia en el pool génico de la población mestiza peruana actual. El haplogrupo E-M2 se ha identificado en población asháninca (Fonseca Pinto Leite, 2018), y el E-PF2477, en el estudio de Sandoval y colaboradores (2018); estos subhaplogrupos son característicos de poblaciones africanas (Trombetta et al., 2011).
La posible explicación a las diferencias observadas entre la población de Trujillo y la mayoría de las de Argentina es la cantidad y diversidad en la procedencia de los inmigrantes que cada una de las regiones recibió a partir del siglo XIX (Lattes, 1985; Hunefeldt, 2004). El desarrollo económico es un factor de atracción y un determinante en la dirección y asentamiento de la corriente migratoria, particularmente cuando se trata de desplazamiento de la fracción masculina. En torno a las ciudades más grandes, se puede apreciar un componente alóctono más acentuado, al menos en la experiencia de trabajo que nuestro grupo tiene en Argentina (Bailliet et al., 2011). De hecho, en las últimas décadas, se destaca una fuerte tendencia de ciudadanos peruanos a migrar hacia Argentina, atraídos por las demandas del mercado laboral (Macchiavello, 2009).
Por otro lado, el bajo nivel de diferenciación entre la muestra de Trujillo y algunas localidades de Argentina (La Quiaca, San Salvador de Jujuy, Salta y Santa María, todas ubicadas en la región Noroeste), puede explicarse por la relativamente alta proporción de linajes nativos Q-M3. El Noroeste integra el amplio espacio cultural de los Andes Centrales en Sudamérica. Formó parte del Collasuyo, la región sur del Imperio inca y de otros fenómenos culturales prehispánicos como Tiawanako-Wari, el complejo arqueológico Yavi-Isla y Aguada (1400 AP) (Muzzio et al., 2018). Sin embargo, el estudio de los haplogrupos del cromosoma Y no permite profundizar aún en la diferenciación regional dentro del componente nativo. Futuros estudios centrados en la variabilidad interna contribuirán a enriquecer la discusión sobre la dinámica poblacional propia del mundo andino. Desde una perspectiva histórica -comenzando por la época precolombina, el surgimiento del Imperio inca y sus estrategias de expansión y reemplazo (Stanish, 2001; Salazar Burger, 2004; Tung, 2008)-, los datos sustentan las expectativas acerca de su posible impacto en la actual estructura genética de las poblaciones.
Conclusión
Se logró identificar y caracterizar linajes autóctonos y alóctonos para la población de Trujillo. Tal como se esperaba, esta población presenta una ancestralidad predominantemente nativa, pero cuenta, además, con una relativamente alta incidencia de linajes paternos de origen europeo. Los resultados obtenidos son coherentes con la historia migratoria de Sudamérica. La población en estudio se asemeja genéticamente a las localidades del extremo norte de Argentina. Estas últimas se encuentran próximas al límite con Bolivia y, además de compartir una historia demográfica común, han mantenido un flujo de migrantes a lo largo del tiempo.